Кластерный анализ
Кластерный анализ объединяет различные процедуры, используемые для проведения классификации. Под кластером понимают группу объектов, обладающую свойством плотности, дисперсией, отделимостью от других кластеров, формой, размером.
Задача сложна тем, что мы сравниваем страны не по - одному какому - либо параметру, а по нескольким параметрам одновременно.
Использование кластер-анализа для решения данной задачи наиболее эффективно. В общем случае кластер-анализ предназначен для объединения некоторых объектов в классы (кластеры) таким образом, чтобы в один класс попадали максимально схожие, а объекты различных классов максимально отличались друг от друга. Количественный показатель сходства рассчитывается заданным способом на основании данных, характеризующих объекты.
Шаг первый - Иерархическая классификация. Для начала работы в статистике запускаем таблицу с данными. Далее выбираем Кластерный анализ, а в рабочем окне программы STATISTICA выбираем пункт Анализ, затем стартовую панель самого Кластерного анализа. Выбираем метод Иерархической кластеризации. Выбираем нужные переменные, в поле Объекты выбираем Наблюдения (строки). В качестве правила объединения отмечаем Метод полной связи, в качестве меры близости - Евклидово расстояние.
Метод полной связи определяет расстояние между кластерами как наибольшее расстояние между любыми двумя объектами в различных кластерах (т.е. "наиболее удаленными соседями"). Мера близости, определяемая евклидовым расстоянием, является геометрическим расстоянием в n- мерном пространстве.
Наиболее важным результатом, получаемым в результате древовидной кластеризации, является иерархическое дерево. Выбираем опцию Вертикальная диаграмма.
На рисунке 7, представленном ниже, получили результат, который включил в себя следующие данные: количество переменных, равные 9, количество наблюдаемых стран - 65, правило объединения и метрику расстояния. Эти данные будем использовать для построения диаграммы результата, где страны будут разбиты на кластеры.
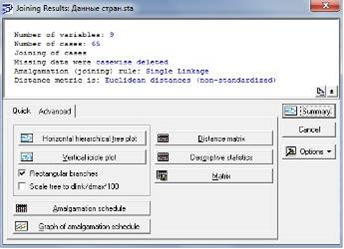
Рисунок 7 - Результат вычислений
Каждый узел диаграммы, приведенной ниже на рисунке 8, представляет объединение нескольких кластеров, положение узлов на вертикальной оси определяет расстояние, на котором были объединены соответствующие кластеры. На расстоянии 500 можно выделить 3 класса, в него попали следующие страны - Китай, Германия и Япония.
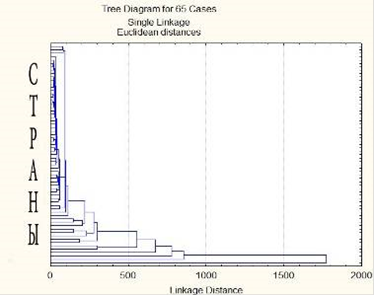
Рисунок 8 - Диаграмма результата
Второй шаг - Кластеризация методом К-средних. Исходя из визуального представления результатов, можно сделать предположение, что страны образуют около семи естественных кластеров. Проверим данное предположение, разбив исходные данные методом К-средних на 7 кластеров, и проверим значимость различия между полученными группами. В Стартовой панели модуля Кластерный анализ выбираем Кластеризация методом К средних. Получаем результаты дисперсионного анализ (рисунок 9).
Исходя из амплитуды (и уровней значимости) F-статистики, все переменные являются главными при решении вопроса о распределении объектов по кластерам.
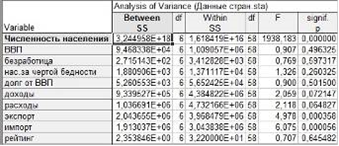
Рисунок 9 - Результат дисперсионного анализа
Немного больше об экономике сегодня
Инновационная деятельность малых предприятий Ростовской области
инновационный малый бизнес целевой
Преодоление
последствий мирового экономического кризиса и выход России на качественно новый
уровень технического и экономического развития невозможен без активизации
инновационных процессов. Менее ощутимое снижение инновационной активности малых
предприятий с одной стороны связан ...
Интеллектуальная рента как фактор развития инновационной экономики
Экономическое и общественное развитие на современном этапе
характеризуется тем, что информация, знания, научные достижения, инновации
выходят на первый план. Если ранее ренту рассматривали применительно к
природным ресурсам, то теперь многие исследователи склоняются к выделению в
экономической структуре рентных и ...